元ネタ: Tarvainen and Valpola, Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results, 2017
図表は特に断りがない限りこの論文から引用
Temporal Ensemblingでは,あるデータ点に対して過去に計算した結果のexponential moving average(EMA)を教師モデルの出力としていた.この場合教師モデルが過去のエポックで決まるから,第 エポックで学習してきた情報が教師モデルに統合されておらず,データセットが大きいほど学習のペースが遅くなってしまい,また過去のすべてのデータ点に対する出力を保持する必要がある.
そこで著者らは前のイテレーションにおけるネットワークの重みのEMAを教師モデルとする方法を考え,Mean Teacherと名付けた.
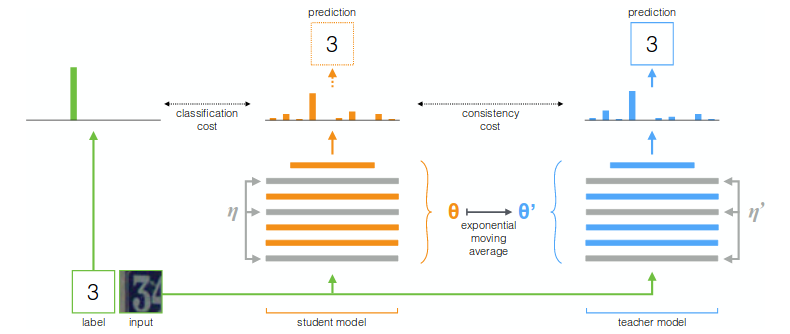
fig.1 Mean Teacherのダイアグラム
0 件のコメント:
コメントを投稿