元ネタ: Tzeng et al. Deep Domain Confusion: Maximizing for Domain Invariance, 2014
図表は特に断りがない限りこの論文から引用
Domain adaptationのメソッド.ネットワークがsource domainとtarget domainに共通する表現を学習し,かつsource domainで優れた分類モデルとなるようにすれば,target domainにおいても優れた分類を行えるはずである(fig.1).
そこで,source, target domainにおける表現の距離をMaximum Mean Discrepancy(MMD)と定義しdomain (confusion) lossとよび,classification lossとの和を最適化する.をネットワークとして
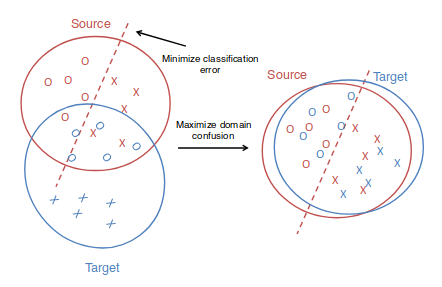
figure 1. domain confusion概念図
Deep domain confusionでは,fc_adapt層以外のパラメータを共有するネットワークを2つ用意し,ラベルのついたデータ店に対してのみclassification loss を計算し,さらにすべてのデータ点でdomain lossを計算し,その和を最適化する.(fig.2).
fc_adaptはそれぞれのネットワークで異なり,source domainとtarget domainの違いを吸収する.
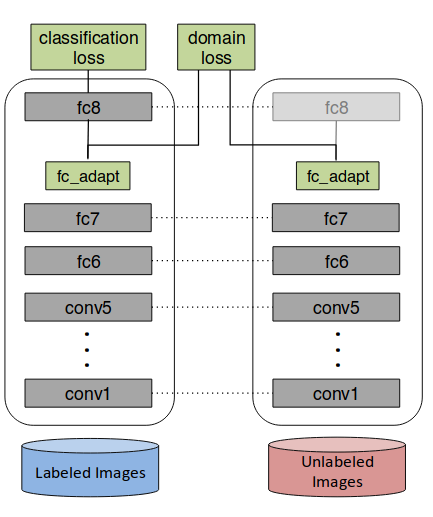
figure 2. Deep Domain Confusion 概念図(破線はパラメータの共有を意味する)
このメソッドはadversarial learningとして見ることもできる(らしいSaito et al, 2017).
conv1 - fc7をgenerator, fc_adaptをdiscriminator(critic), fc8をclassifierとして,discriminatorがsource domain, target domainを区別できないようにgeneratorを学習すると同時に,classifierが正しくクラス分類を行うように学習するのである(fc_adaptをdomain lossが大きくなるように学習していないのが気になるところだ).
0 件のコメント:
コメントを投稿