The 1 cycle policy
著者の過去の論文では,learning rateを図1のように,イテレーションの間で何度も大きくしたり小さくしたり変化させる(boundaryの決め方は後で).この,小さなlearning rateがmax_lrに至り,またもう一度base_lrになるまでを著者はcycleと呼んでいる.
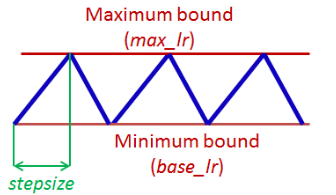 図1
図1
一方,この論文では図2のように,最初は小さいlearning rateから初めて,全学習過程においてただ1度だけcycleを回し,最後にbase_lrよりも小さいlearning rateに線形に変化させている.
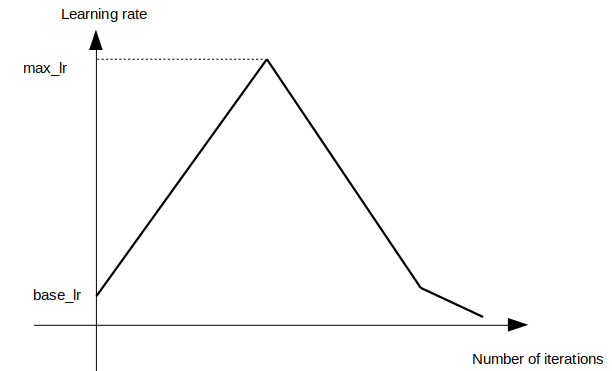 図2
図2
また,learning rateとmomentumがともに大きいと学習が不安定になるので,momentumは図3のようにlearning rateとは反対の方向に減らしたり増やしたりすることを提案している.
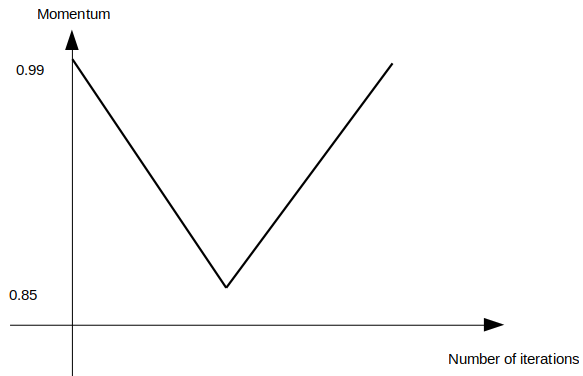 図3
図3
これによって高速かつ高性能なモデルが学習できるという.
また著者は大きなlearning rateはregularizationに有益と主張していて,そのため他のregularizationの手法の力を弱めるべきだと主張している.例えばweight decayやdropoutの係数を小さくするなどである.
max_lr, base_lrの決め方
学習を小さなlearning rateから初めて徐々に大きくしていく.最初はvalidation errorは小さくなっていくが,ある値からはvalidation errorが発散を始める.このときの値をmax_lrとし,base_lrはmax_lrの0.1~0.05倍とする.
(イテレーション回数は試行錯誤して決めるしかないようだ)