元ネタ: Novotny et al. Semi-convolutional Operators for Instance Segmentation
インスタンスセグメンテーションやバウンディングボックスでない物体検出のため,Semi-convolutionを提案する.
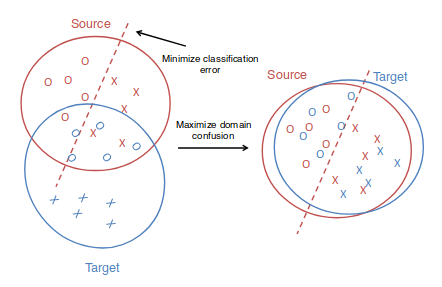
RCNNやYolo, SSDといった物体検出器は,物体がありそうな領域のproposalを計算し,さらにそこからその物体によくあるバウンディングボックスの座標を計算する(Propose and Verify, P&V)のだが,バウンディングボックスはほとんどの場合物体の位置のあらい近似だし,そこから改めて物体の詳細な位置を計算するには手間がかかる.そのため,画像のすべてのピクセルについて,"同じ物体に属するピクセルには同じ色をつけ,異なる物体に属するピクセルには異なる色をつける"という方法(Instance Coloring, IC)がより適していると考えられる.この定性的な優位性にかかわらずICがよい性能を示さないのはCNNのtranslation invarianceによるものと考え,translation variantなSemi-convolutionを提案する.
Instance Coloringを行う(理想的な)CNNΦ \Phi Φ X \mathcal{X} X L \mathcal{L} L Ω \Omega Ω S = ( S 1 , . . . ) \mathcal{S}=(S_1, ...) S = ( S 1 , . . . ) ∀ u , v ∈ Ω : { ∥ Φ u ( x ) − Φ v ( x ) ∥ ≤ 1 − M , ∃ k : u , v ∈ S k ∥ Φ u ( x ) − Φ v ( x ) ∥ ≤ 1 + M , otherwise \forall u, v \in \Omega: \begin{cases} \|\Phi_u(\mathbf{x}) - \Phi_v(\mathbf{x})\| \leq 1 - M , \exists k: u, v \in S_k \\\|\Phi_u(\mathbf{x}) - \Phi_v(\mathbf{x})\| \leq 1 + M , \text{otherwise}\end{cases} ∀ u , v ∈ Ω : { ∥ Φ u ( x ) − Φ v ( x ) ∥ ≤ 1 − M , ∃ k : u , v ∈ S k ∥ Φ u ( x ) − Φ v ( x ) ∥ ≤ 1 + M , otherwise Ψ \Psi Ψ Φ u ( x ) = f ( ϕ u ( x ) , u ) \Phi_u (\mathbf{x}) = f(\phi_u(\mathbf{x}), u) Φ u ( x ) = f ( ϕ u ( x ) , u ) f : L × Ω → L ′ f:\mathcal{L} \times \Omega \rightarrow \mathcal{L}' f : L × Ω → L ′ Ψ u ( X ) = Φ u ( x ) + u , ϕ u ( x ) ∈ L = R 2 \Psi_u(\mathbf{X}) = \Phi_u(\mathbf{x}) + u, \phi_u(\mathbf{x}) \in \mathcal{L}=\mathbf{R}^2 Ψ u ( X ) = Φ u ( x ) + u , ϕ u ( x ) ∈ L = R 2 ∀ u ∈ S k , Ψ u ( x ) + u = c k \forall u \in S_k, \Psi_u(\mathbf{x}) + u = c_k ∀ u ∈ S k , Ψ u ( x ) + u = c k c k c_k c k c k c_k c k Ψ \Psi Ψ u u u c k c_k c k
もちろんラベル空間L \mathcal{L} L Ψ u ( x ) = u ^ + Φ u ( x ) , u ^ = [ u x , u y , 0 , . . . , 0 ] T ∈ R d \Psi_u(x) = \hat{u} + \Phi_u(\mathcal{x}), \hat{u} = [u_x, u_y ,0 ,..., 0]^T \in \mathbf{R}^d Ψ u ( x ) = u ^ + Φ u ( x ) , u ^ = [ u x , u y , 0 , . . . , 0 ] T ∈ R d
学習の際のlossはL ( Φ ∣ x , S ) = ∑ S ∈ S ∥ Ψ u ( x ) − 1 ∣ S ∣ ∑ S ∈ S Ψ u ( x ) ∥ \mathcal{L}(\Phi|\mathbf{x}, \mathbf{S}) = \sum_{S \in \mathcal{S}} \left \| \Psi_u(\mathbf{x}) - \frac{1}{|S|} \sum_{S \in \mathcal{S}} \Psi_u(\mathbf{x}) \right\| L ( Φ ∣ x , S ) = S ∈ S ∑ ∥ ∥ ∥ ∥ ∥ Ψ u ( x ) − ∣ S ∣ 1 S ∈ S ∑ Ψ u ( x ) ∥ ∥ ∥ ∥ ∥