元ネタ: Tzeng and Saenko, Simultaneous Deep Transfer Across Domains and Tasks, 2015, ICCV 2015
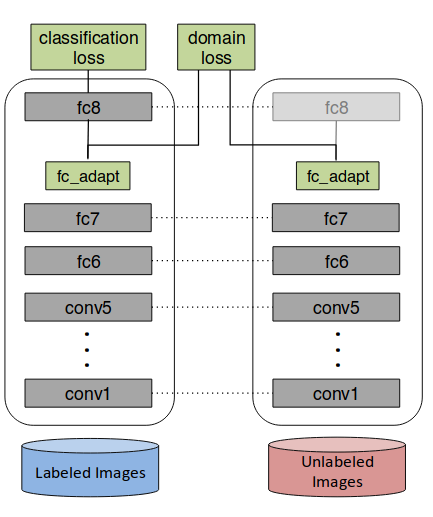
figure 1. Deep Domain Confusionのダイアグラム
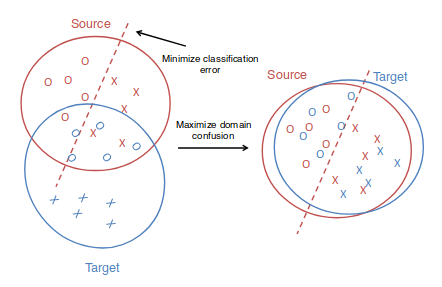
Tzengの前の論文では,source domain での分類と並行して,sourceとtargetに対して生成する表現が似てくるように学習させるため,confusion loss
をも最適化するように学習させた(fig.1).しかしdomain同士の表現が似ていてもそれぞれの内部でdecision boundaryが似ているかは別の話だから,この論文では表現の構造のみならずsource domainのラベルの構造をtarget domainに変換する.変換にはtarget domainにいくつかラベル付きの点が必要だから,unsupervised domain adaptationに直接適用することはできない.
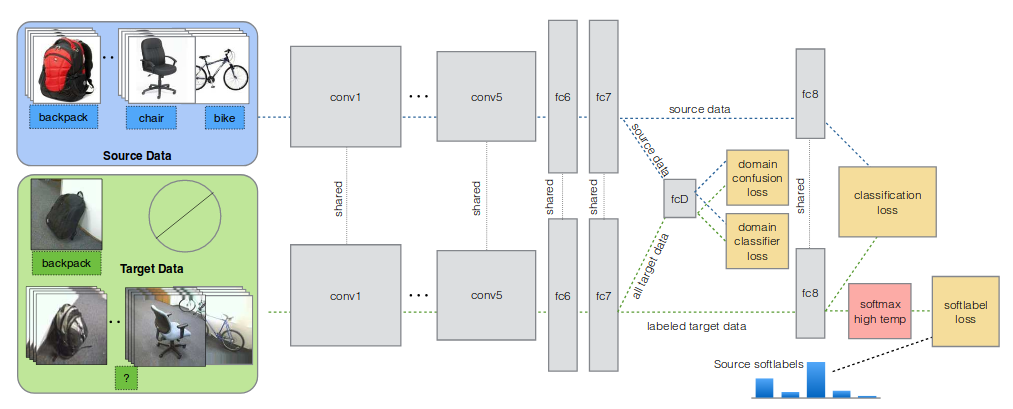
figure 2. Simultaneous Deep Transferのダイアグラム
domain confusionによって表現を似せる
インプットからfc7までを,表現を生成するネットワークGとし,Gの出力する表現がsource domainから来たのかtarget domainから来たのか区別するネットワークfcDを構成する.fcDは通常のnegative log likelihoodによって最適化する.つまり損失関数は
ただしはfcDの重みで,はfcDの結果のlogit.
さらにfcDを騙すようにGを最適化する(adversarial learning).損失関数は
sourceからtargetへのクラス構造のadaptation
通常ニューラルネットワークの(Kクラスの)クラス分類では,最終層にK個のニューロンを配置し,その出力にsoftmaxをかけてそのargmaxに対応するクラスをそのネットワークの推測とするわけだが,ここではsoftmaxの出力そのものに様々な操作を行っていく.
特に,あるクラスに対応するデータ点全てのsoftmaxの出力の平均を"soft label"と定義する(fig.3).ただし通常のsoftmaxはピークが強調されすぎるので,softmaxの温度を高くする.
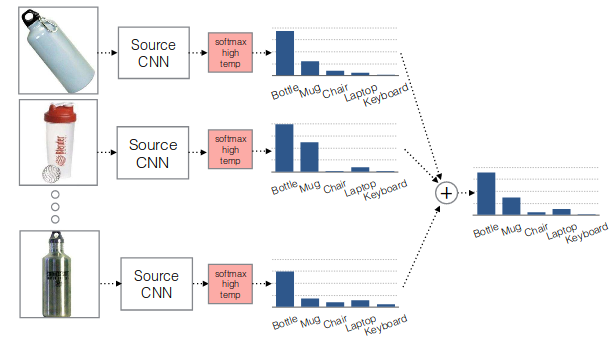
figure 3. soft label概念図
これによってsource domainにおける各くらすにおけるsoft labelが計算できる.これらのsoft labelに対して,ラベル付きのtarget domainの点に対して損失関数を
とする.ただしはに対するsoft activation, はsource domainのクラスiに対応するsoft label,
この損失というのはtargetのsoft activationとsourceのsoft labelの,targetクラスにおけるcross-entropyに等しい(fig.4).
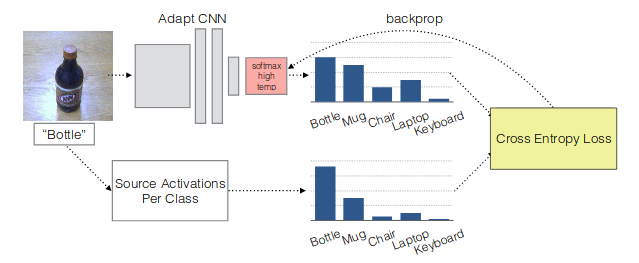
figure 4. soft loss
以上のlossを最適化する.
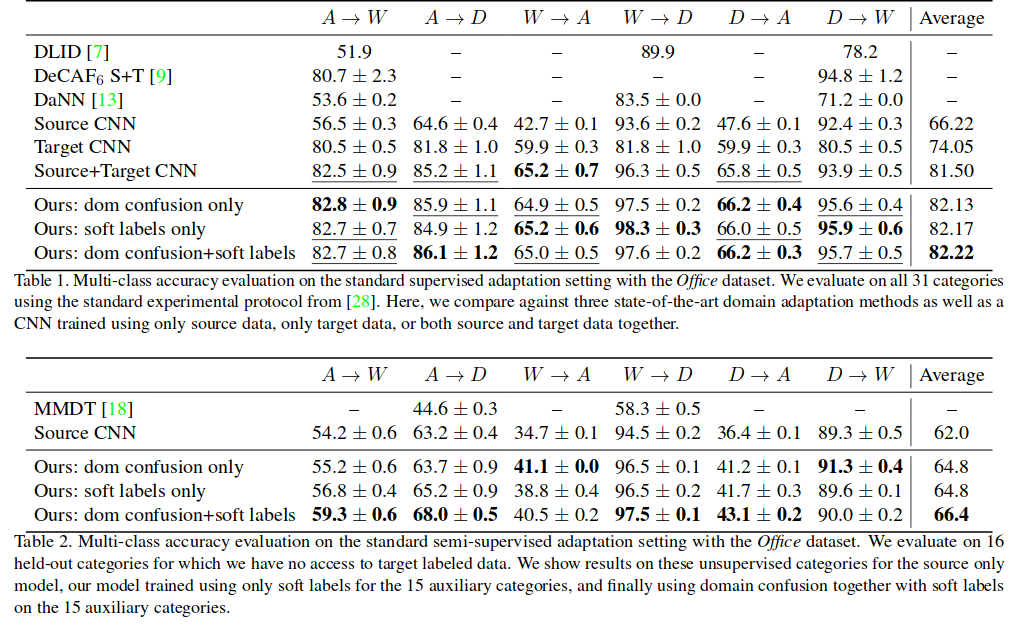
結果