元ネタ: French and Mackewicz, Self-ensembling for visual domain adaptation, 2018
図表は特に断りがない限りこの論文から引用
Mean Teacherモデルをdomain adaptationに転用. VisDA-17 Classification 優勝
Domain adaptationとは
“新規タスクの効果的な仮説を効率的に見つけ出すために,一つ以上の別のタスクで学習された知識を得て,それを適用する問題”(朱鷺の杜)
例えば人・自動車・犬・猫といった物体の絵のデータセットから分類モデルを学習し,それらの写真を分類するような問題のことである.学習を行うドメインをsource domain,モデルを適用したいドメインをtarget domainという.この例では絵がsource domainで,写真がtarget domainとなる.
VISDA-2017では3次元モデルから生成した画像をsource domainに,写真をtarget domainとして,domain adaptationモデルを競った.なお,source domainではすべてのデータ点にラベルが与えられ,target domainではunsupervisedな学習が許された.
Self-ensembling for visual domain adaptation
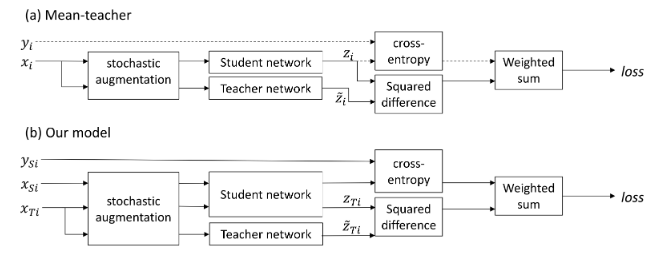
fig.1 (a) mean-teacher (b) self-ensembling for visual domain adaptation
(a)における破線はラベルが与えられた場合にのみ実行されることを示している.
source domainとtarget domainをそれぞれとする.には対応するラベルが与えられており,それをとする. Mean-teacherでは,CrossEntropyによるLossはラベルが与えられた場合にのみ最適化していたが,self-ensembling for visual domain adaptationでは教師モデルがtarget domainのデータ点のクラスを推測し,それがconfidence threshold以上であれば,そのラベルを教師データとして生徒モデルの出力とCrossEntropyをlossとして最適化する.
0 件のコメント:
コメントを投稿