元ネタ: Samuli Laine and Timo Aila, Temporal Ensembling for Semi-Supervised Learning, 2017, ICLR 2017
図表は特に断りがない限りこの論文から引用
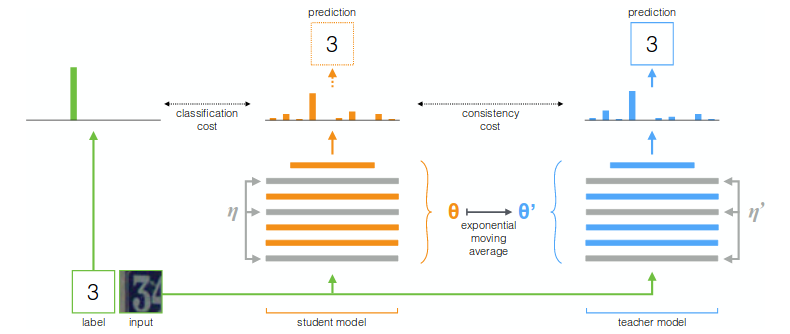
複数のモデルのensembleは教師の有無にかかわらずよく使われる手法で,dropoutによる性能向上も内部で複数のモデルのensembleが起きているためだという人もいる.この論文ではdropout(とdata augmentation)によるensembleによって高精度な教師モデルを構成し,生徒モデルが教師モデルの出力を真似ることで半教師あり学習を行う.
Data Distillatinを思い出すが,Data Distillationは教師モデルがハードなラベル(すなわちクラスラベルそのもの)を推測してNLLやCrossEntropyをLossとして生徒モデルを最適化したのに対し,こちらでは同じ入力からの教師モデルと生徒モデルの出力の差異をLossとする. またラベル付きのデータ点に対してのみ,CrossEntropyをLossに足して最適化する.
dropoutの場所を変えてensembleを行うΠ-modelと,過去のepochにおける出力とensembleを行うTemporal ensemblingが提案されている.
Π-model
同じexample xについて,確率的なaugmentationやdropoutによってニューラルネットワークfθは非決定的な関数だから,z=fθ(x),z~=fθ(x)は異なっているはずで,その差異∥z−z~∥を小さくする.さらにxがラベル付きであるとき,z,z~とそのラベルの乖離を小さくする.この場合,教師モデルと生徒モデルは同じものである.

fig.1 Π-modelのダイアグラム

fig.2 Π-modelのアルゴリズム
Temporal ensembling
Π-modelではネットワークのパラメータθを変えずにz,z~を計算したが,Temporal ensemblingでは過去のepochで計算した値のexponential moving averageを教師モデルの出力z~とする.
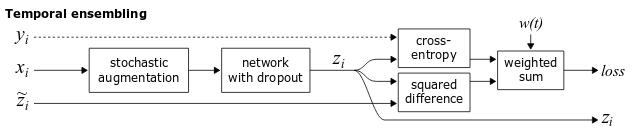
fig.3 Temporal Ensemblingのダイアグラム

fig.4 Temporal Ensemblingのアルゴリズム